

{kind=link}
Just a few months in the past, I wrote concerning the safety of AI fashions, fine-tuning strategies, and the usage of Retrieval-Augmented Era (RAG) in a Cisco Safety Weblog submit. On this weblog submit, I’ll proceed the dialogue on the crucial significance of studying easy methods to safe AI techniques, with a particular concentrate on present LLM implementations and the “LLM stack.”
I additionally not too long ago printed two books. The primary e-book is titled “The AI Revolution in Networking, Cybersecurity, and Rising Applied sciences” the place my co-authors and I cowl the best way AI is already revolutionizing networking, cybersecurity, and rising applied sciences. The second e-book, “Past the Algorithm: AI, Safety, Privateness, and Ethics,” co-authored with Dr. Petar Radanliev of Oxford College, presents an in-depth exploration of crucial topics together with pink teaming AI fashions, monitoring AI deployments, AI provide chain safety, and the appliance of privacy-enhancing methodologies reminiscent of federated studying and homomorphic encryption. Moreover, it discusses methods for figuring out and mitigating bias inside AI techniques.
For now, let’s discover a few of the key elements in securing AI implementations and the LLM Stack.
What’s the LLM Stack?
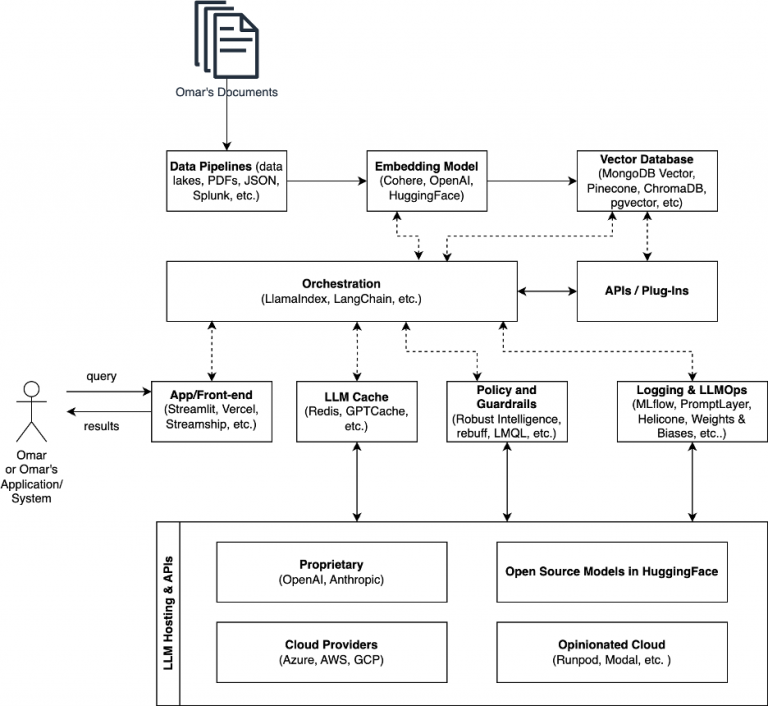
The “LLM stack” usually refers to a stack of applied sciences or parts centered round Giant Language Fashions (LLMs). This “stack” can embody a variety of applied sciences and methodologies geared toward leveraging the capabilities of LLMs (e.g., vector databases, embedding fashions, APIs, plugins, orchestration libraries like LangChain, guardrail instruments, and so forth.).
Many organizations try to implement Retrieval-Augmented Era (RAG) these days. It’s because RAG considerably enhances the accuracy of LLMs by combining the generative capabilities of those fashions with the retrieval of related info from a database or data base. I launched RAG on this article, however in brief, RAG works by first querying a database with a query or immediate to retrieve related info. This info is then fed into an LLM, which generates a response primarily based on each the enter immediate and the retrieved paperwork. The result’s a extra correct, knowledgeable, and contextually related output than what may very well be achieved by the LLM alone.
Let’s go over the everyday “LLM stack” parts that make RAG and different purposes work. The next determine illustrates the LLM stack.
Vectorizing Knowledge and Safety
Vectorizing information and creating embeddings are essential steps in getting ready your dataset for efficient use with RAG and underlying instruments. Vector embeddings, also called vectorization, contain reworking phrases and various kinds of information into numerical values, the place every bit of knowledge is depicted as a vector inside a high-dimensional house. OpenAI affords completely different embedding fashions that can be utilized by way of their API. You may also use open supply embedding fashions from Hugging Face. The next is an instance of how the textual content “Instance from Omar for this weblog” was transformed into “numbers” (embeddings) utilizing the text-embedding-3-small mannequin from OpenAI.
"object": "checklist",
"information": [
{
"object": "embedding",
"index": 0,
"embedding": [
0.051343333,
0.004879803,
-0.06099363,
-0.0071908776,
0.020674748,
-0.00012919278,
0.014209986,
0.0034705158,
-0.005566879,
0.02899774,
0.03065297,
-0.034541197,
<output omitted for brevity>
]
}
],
"mannequin": "text-embedding-3-small",
"utilization": {
"prompt_tokens": 6,
"total_tokens": 6
}
}
Step one (even earlier than you begin creating embeddings) is information assortment and ingestion. Collect and ingest the uncooked information from completely different sources (e.g., databases, PDFs, JSON, log information and different info from Splunk, and so forth.) right into a centralized information storage system referred to as a vector database.
Observe: Relying on the kind of information you will have to wash and normalize the info to take away noise, reminiscent of irrelevant info and duplicates.
Making certain the safety of the embedding creation course of entails a multi-faceted method that spans from the collection of embedding fashions to the dealing with and storage of the generated embeddings. Let’s begin discussing some safety issues within the embedding creation course of.
Use well-known, business or open-source embedding fashions which have been completely vetted by the group. Go for fashions which can be broadly used and have a robust group help. Like all software program, embedding fashions and their dependencies can have vulnerabilities which can be found over time. Some embedding fashions may very well be manipulated by risk actors. For this reason provide chain safety is so essential.
You also needs to validate and sanitize enter information. The information used to create embeddings might include delicate or private info that must be protected to adjust to information safety laws (e.g., GDPR, CCPA). Apply information anonymization or pseudonymization strategies the place attainable. Be certain that information processing is carried out in a safe atmosphere, utilizing encryption for information at relaxation and in transit.
Unauthorized entry to embedding fashions and the info they course of can result in information publicity and different safety points. Use sturdy authentication and entry management mechanisms to limit entry to embedding fashions and information.
Indexing and Storage of Embeddings
As soon as the info is vectorized, the following step is to retailer these vectors in a searchable database or a vector database reminiscent of ChromaDB, pgvector, MongoDB Atlas, FAISS (Fb AI Similarity Search), or Pinecone. These techniques enable for environment friendly retrieval of comparable vectors.
Do you know that some vector databases don’t help encryption? Guarantee that the answer you employ helps encryption.
Orchestration Libraries and Frameworks like LangChain
Within the diagram I used earlier, you’ll be able to see a reference to libraries like LangChain and LlamaIndex. LangChain is a framework for creating purposes powered by LLMs. It permits context-aware and reasoning purposes, offering libraries, templates, and a developer platform for constructing, testing, and deploying purposes. LangChain consists of a number of elements, together with libraries, templates, LangServe for deploying chains as a REST API, and LangSmith for debugging and monitoring chains. It additionally affords a LangChain Expression Language (LCEL) for composing chains and offers customary interfaces and integrations for modules like mannequin I/O, retrieval, and AI brokers. I wrote an article about quite a few LangChain sources and associated instruments which can be additionally accessible at one in all my GitHub repositories.
Many organizations use LangChain helps many use circumstances, reminiscent of private assistants, query answering, chatbots, querying tabular information, and extra. It additionally offers instance code for constructing purposes with an emphasis on extra utilized and end-to-end examples.
Langchain can work together with exterior APIs to fetch or ship information in real-time to and from different purposes. This functionality permits LLMs to entry up-to-date info, carry out actions like reserving appointments, or retrieve particular information from net providers. The framework can dynamically assemble API requests primarily based on the context of a dialog or question, thereby extending the performance of LLMs past static data bases. When integrating with exterior APIs, it’s essential to make use of safe authentication strategies and encrypt information in transit utilizing protocols like HTTPS. API keys and tokens ought to be saved securely and by no means hard-coded into the appliance code.
AI Entrance-end Functions
AI front-end purposes consult with the user-facing a part of AI techniques the place interplay between the machine and people takes place. These purposes leverage AI applied sciences to offer clever, responsive, and personalised experiences to customers. The entrance finish for chatbots, digital assistants, personalised advice techniques, and lots of different AI-driven purposes could be simply created with libraries like Streamlit, Vercel, Streamship, and others.
The implementation of conventional net utility safety practices is crucial to guard in opposition to a variety of vulnerabilities, reminiscent of damaged entry management, cryptographic failures, injection vulnerabilities like cross-site scripting (XSS), server-side request forgery (SSRF), and lots of different vulnerabilities.
LLM Caching
LLM caching is a method used to enhance the effectivity and efficiency of LLM interactions. You should utilize implementations like SQLite Cache, Redis, and GPTCache. LangChain offers examples of how these caching strategies may very well be leveraged.
The fundamental thought behind LLM caching is to retailer beforehand computed outcomes of the mannequin’s outputs in order that if the identical or related inputs are encountered once more, the mannequin can rapidly retrieve the saved output as a substitute of recomputing it from scratch. This may considerably cut back the computational overhead, making the mannequin extra responsive and cost-effective, particularly for continuously repeated queries or widespread patterns of interplay.
Caching methods should be rigorously designed to make sure they don’t compromise the mannequin’s capability to generate related and up to date responses, particularly in situations the place the enter context or the exterior world data adjustments over time. Furthermore, efficient cache invalidation methods are essential to forestall outdated or irrelevant info from being served, which could be difficult given the dynamic nature of information and language.
LLM Monitoring and Coverage Enforcement Instruments
Monitoring is likely one of the most essential components of LLM stack safety. There are lots of open supply and business LLM monitoring instruments reminiscent of MLFlow. There are additionally a number of instruments that may assist shield in opposition to immediate injection assaults, reminiscent of Rebuff. Many of those work in isolation. Cisco not too long ago introduced Motific.ai.
Motific enhances your capability to implement each predefined and tailor-made controls over Personally Identifiable Info (PII), toxicity, hallucination, matters, token limits, immediate injection, and information poisoning. It offers complete visibility into operational metrics, coverage flags, and audit trails, making certain that you’ve a transparent oversight of your system’s efficiency and safety. Moreover, by analyzing person prompts, Motific lets you grasp person intents extra precisely, optimizing the utilization of basis fashions for improved outcomes.
Cisco additionally offers an LLM safety safety suite inside Panoptica. Panoptica is Cisco’s cloud utility safety resolution for code to cloud. It offers seamless scalability throughout clusters and multi-cloud environments.
AI Invoice of Supplies and Provide Chain Safety
The necessity for transparency, and traceability in AI growth has by no means been extra essential. Provide chain safety is top-of-mind for a lot of people within the trade. For this reason AI Invoice of Supplies (AI BOMs) are so essential. However what precisely are AI BOMs, and why are they so essential? How do Software program Payments of Supplies (SBOMs) differ from AI Payments of Supplies (AI BOMs)? SBOMs serve an important position within the software program growth trade by offering an in depth stock of all parts inside a software program utility. This documentation is crucial for understanding the software program’s composition, together with its libraries, packages, and any third-party code. Then again, AI BOMs cater particularly to synthetic intelligence implementations. They provide complete documentation of an AI system’s many components, together with mannequin specs, mannequin structure, supposed purposes, coaching datasets, and extra pertinent info. This distinction highlights the specialised nature of AI BOMs in addressing the distinctive complexities and necessities of AI techniques, in comparison with the broader scope of SBOMs in software program documentation.
I printed a paper with Oxford College, titled “Towards Reliable AI: An Evaluation of Synthetic Intelligence (AI) Invoice of Supplies (AI BOMs)”, that explains the idea of AI BOMs. Dr. Allan Friedman (CISA), Daniel Bardenstein, and I introduced in a webinar describing the position of AI BOMs. Since then, the Linux Basis SPDX and OWASP CycloneDX have began engaged on AI BOMs (in any other case often known as AI profile SBOMs).
Securing the LLM stack is crucial not just for defending information and preserving person belief but in addition for making certain the operational integrity, reliability, and moral use of those highly effective AI fashions. As LLMs turn into more and more built-in into numerous elements of society and trade, their safety turns into paramount to forestall potential detrimental impacts on people, organizations, and society at massive.
Join Cisco U. | Be part of the Cisco Studying Community.
Comply with Cisco Studying & Certifications
Twitter | Fb | LinkedIn | Instagram | YouTube
Use #CiscoU and #CiscoCert to hitch the dialog.
Share: